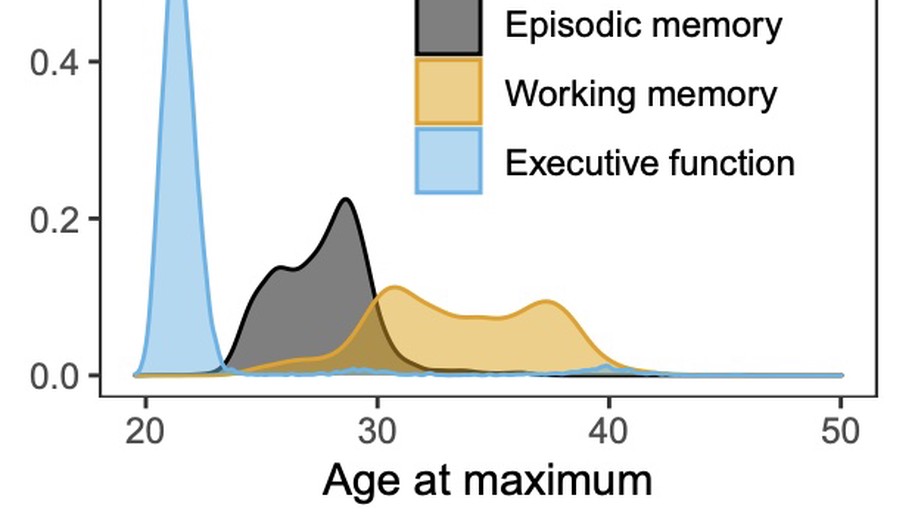
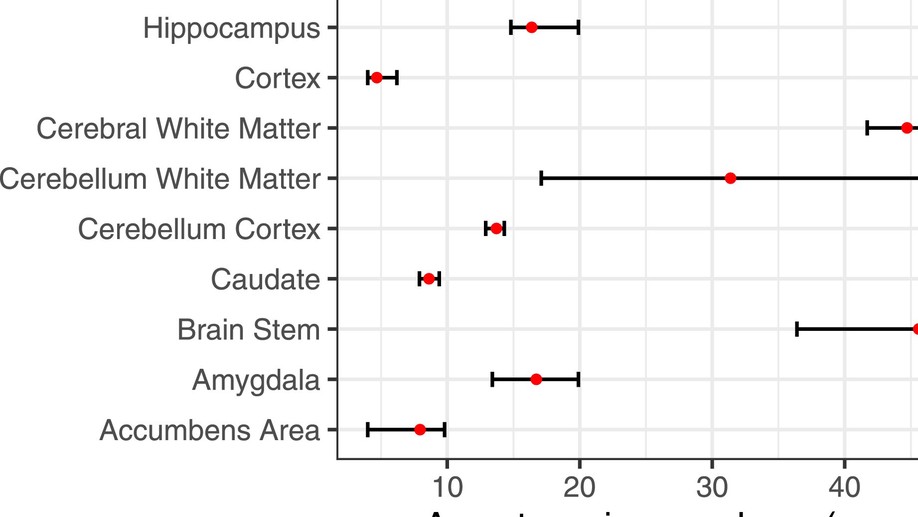
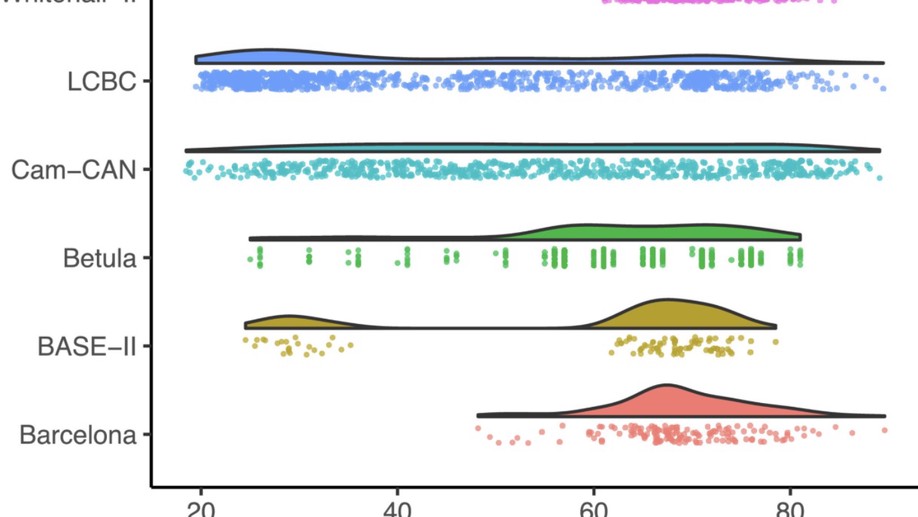
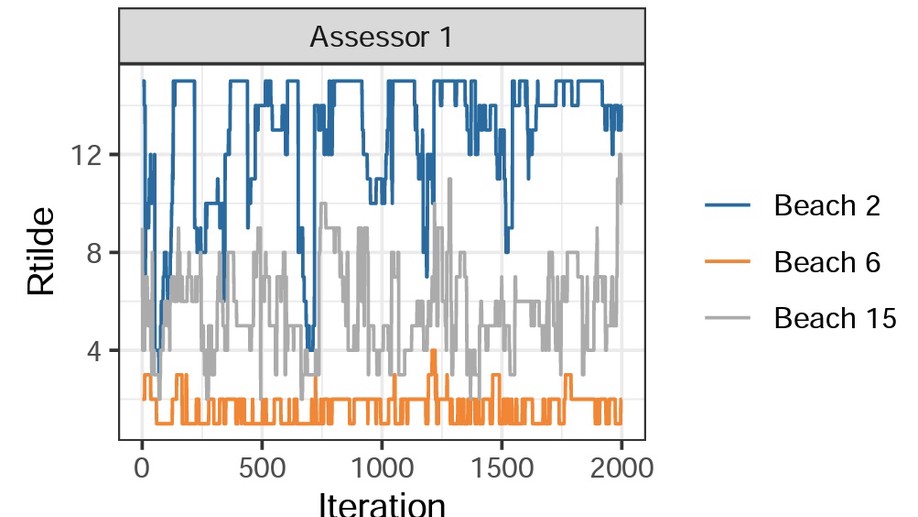
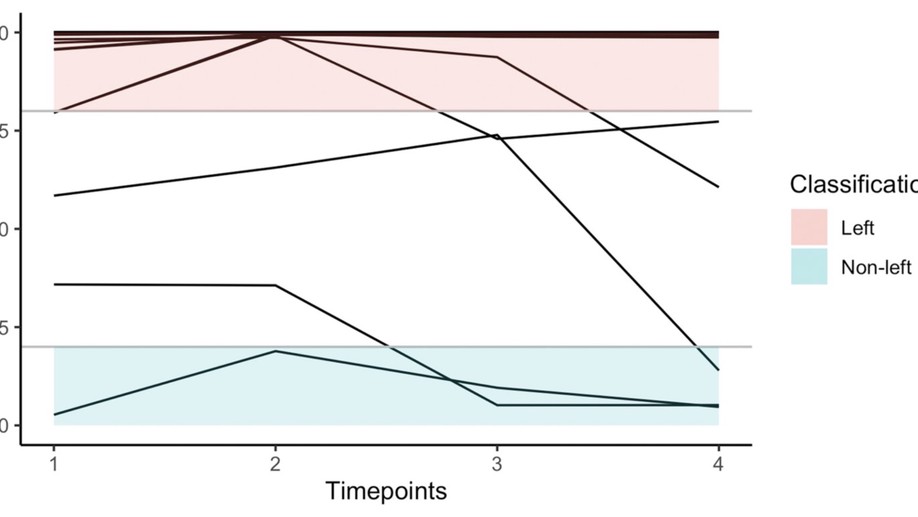
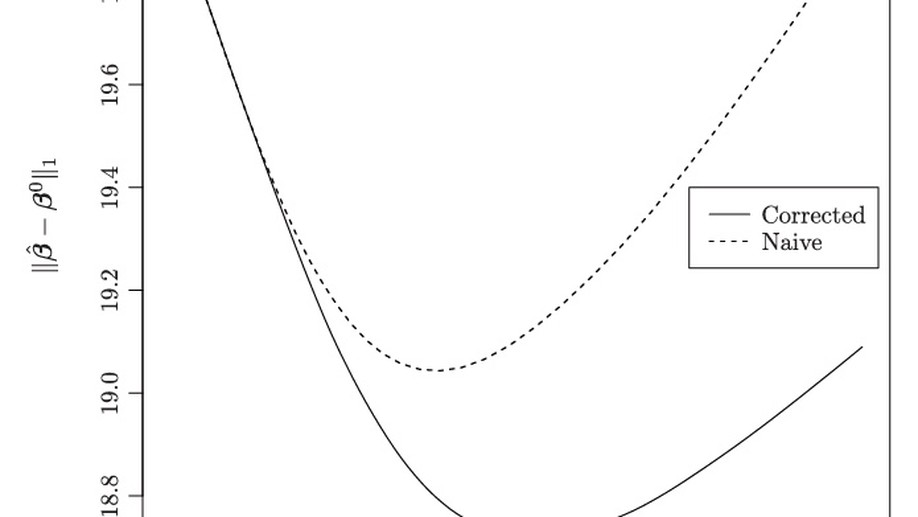
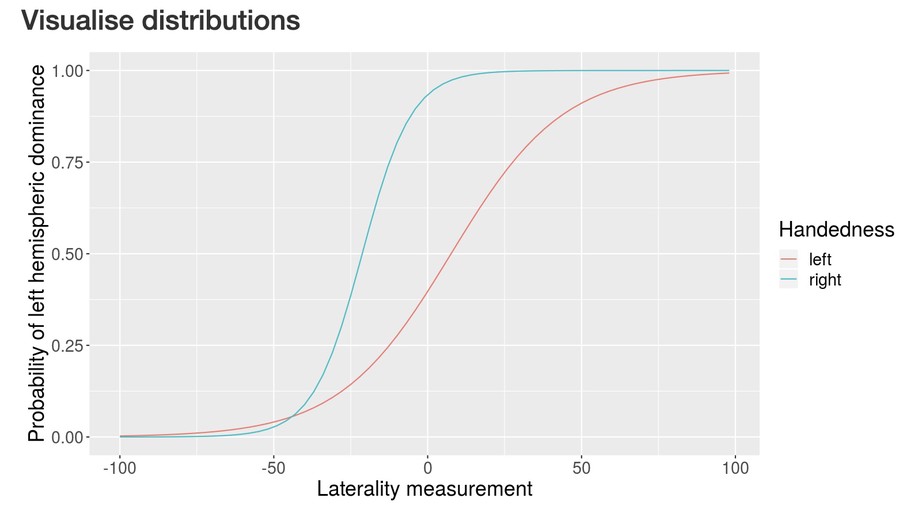
Slides for my presentation at CMStatistics 2021 are available here. The talk was about generalized additive latent and mixed models, which is further described in this post.

I professor of biostatistics at the Department of Psychology, University of Oslo. My research interests include latent variable modeling, rank and preference models, and development of statistical software.
This website summarizes my main statistical publications and research software. Click on the icons to the left to see my full publication list in Google Scholar and all my software projects at GitHub.
Education
-
PhD in Statistics, 2015
University of Oslo
-
MSc in Biological Physics, 2011
Norwegian University of Life Sciences
Interests
- Latent variable modeling
- Computation
- Statistical software